Conditional diffusion models can create unseen images in various settings, aiding image interpolation. Interpolation in latent spaces is well-studied, but interpolation with specific conditions like text or poses is less understood. Simple approaches, such as linear interpolation in the space of conditions, often result in images that lack consistency, smoothness, and fidelity. To that end, we introduce a novel training-free technique named Attention Interpolation via Diffusion (AID). Our key contributions include 1) proposing an inner/outer interpolated attention layer; 2) fusing the interpolated attention with self-attention to boost fidelity; and 3) applying beta distribution to selection to increase smoothness. We also present a variant, Prompt-guided Attention Interpolation via Diffusion (PAID), that considers interpolation as a condition-dependent generative process. This method enables the creation of new images with greater consistency, smoothness, and efficiency, and offers control over the exact path of interpolation. Our approach demonstrates effectiveness for conceptual and spatial interpolation.
We introduce inner/outer interpolated attention and fuse it with self-attention to compute the interpolation path between image generation with different conditions. We further select the specific interpolated images with Beta distribution.
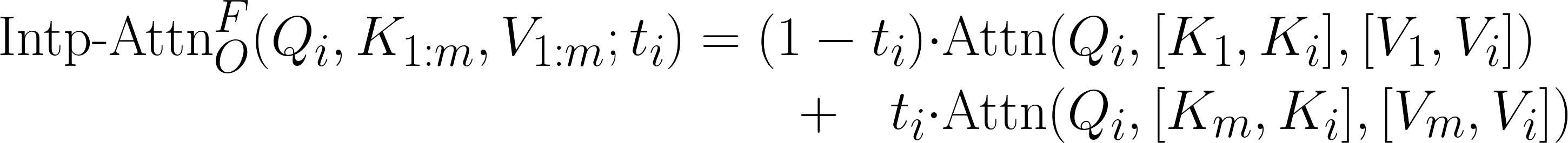
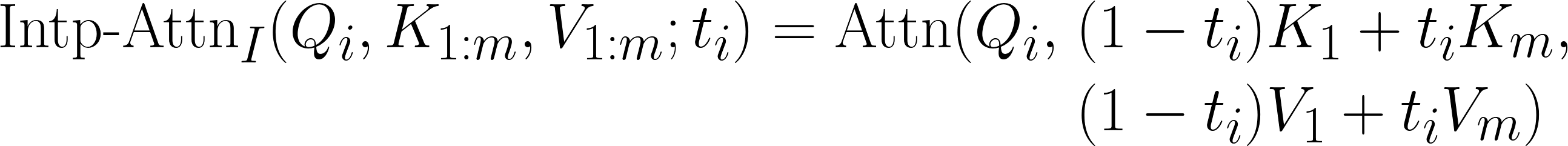
Equations for the inner/outer interpolated attention and the fusion with self-attention.
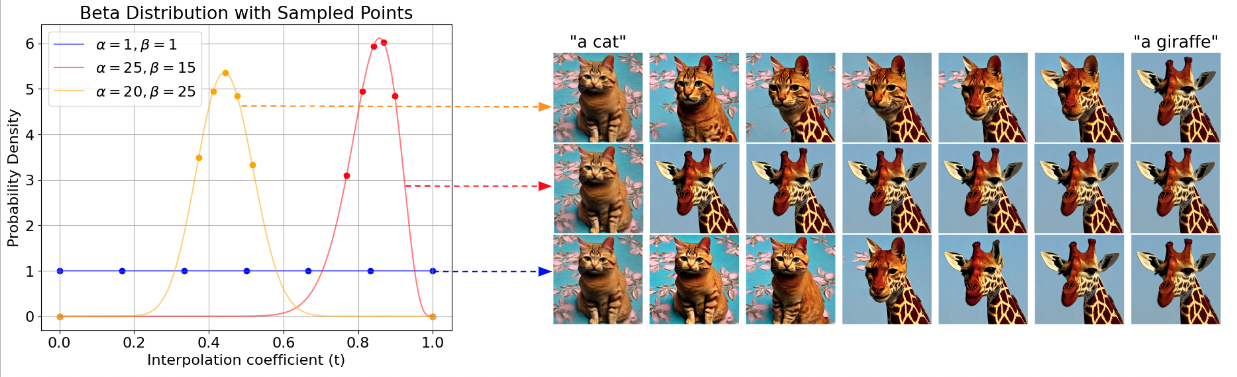
Effect of beta prior and the corresponding interpolation sequence generated by AID.

Qualitative comparison between AID without fusion (1st row), AID with fusion (2nd row) and AID with fusion and beta prior (3rd row).

Based on that, our method rethinks interpolation as a one-to-many task and introduces prompt guidance to determine the specific interpolation sequence.







| Dataset | Method | Smoothness (↑) | Consistency (↓) | Fidelity (↓) |
|---|---|---|---|---|
| CIFAR-10 | Text Embedding Interpolation | 0.7531 | 0.3645 | 118.05 |
| Denoising Interpolation | 0.7564 | 0.4295 | 87.13 | |
| AID-O | 0.7831 | 0.2905* | 51.43* | |
| AID-I | 0.7861* | 0.3271 | 101.13 | |
| LAION-Aesthetics | Text Embedding Interpolation | 0.7424 | 0.3867 | 142.38 |
| Denoising Interpolation | 0.7511 | 0.4365 | 101.31 | |
| AID-O | 0.7643 | 0.2944* | 82.01* | |
| AID-I | 0.8152* | 0.3787 | 129.41 |
Performance on CIFAR-10 and LAION-Aesthethics, where the best performance is marked as (*) and the worst is marked as red. AID-O and AID-I both show significant improvement over the Text Embedding Interpolation. Though Denoising Interpolation achieves relatively high fidelity, but trade-off with very bad performance on consistency (0.4295). AID-O boosts the performance in terms of consistency and fidelity while AID-I boosts the performance of smoothness.
If you find our work useful, please consider citing our paper:
@misc{he2024aid,
title={AID: Attention Interpolation of Text-to-Image Diffusion},
author={Qiyuan He and Jinghao Wang and Ziwei Liu and Angela Yao},
year={2024},
eprint={2403.17924},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
}